The Ultimate Guide to Cloud Native Secret Management

Secret management is the process of protecting sensitive information such as credentials, keys, and certificates throughout their entire lifecycle.
This security topic is a real headache to solve completely, as without a pragmatic approach it can lead to going down a seemingly never-ending series of rabbit holes as there is no perfect one size fits all solution available.
Adopting a solution across an entire organization is challenging – Many solutions solve the problem for a single specific use case which results in gaps when looking at the bigger picture, and others have a prohibitively high barrier to entry due to the amount of effort required across both engineering and process perspectives. Solving all secret management issues swiftly may not be achievable, in which your first milestone should be to understand what a comprehensive future state for your organization resembles. Focus on the tackling low-hanging fruit initially (such as removing plaintext secrets from source control) then build upon it and towards a more complete solution.
Protecting application secrets is the focus here, and whilst there is some overlap with employee secret management, it is beyond the scope of this post. Just be aware that both topics exist and have slightly different concerns.
The initial trust problem
Your application or instance needs a mechanism of authenticating itself with its secret store / key management to either retrieve or decrypt its secrets, this is usually in the form of another secret which must then be managed out of band to secrets inside the secret store.
Establishing initial trust with your secret management tooling is a common problem you will encounter. Some solutions offer more creative approaches for handling this, but it’s important to recognize that this problem is always going to exist, and you often end up simply moving this problem down the stack.
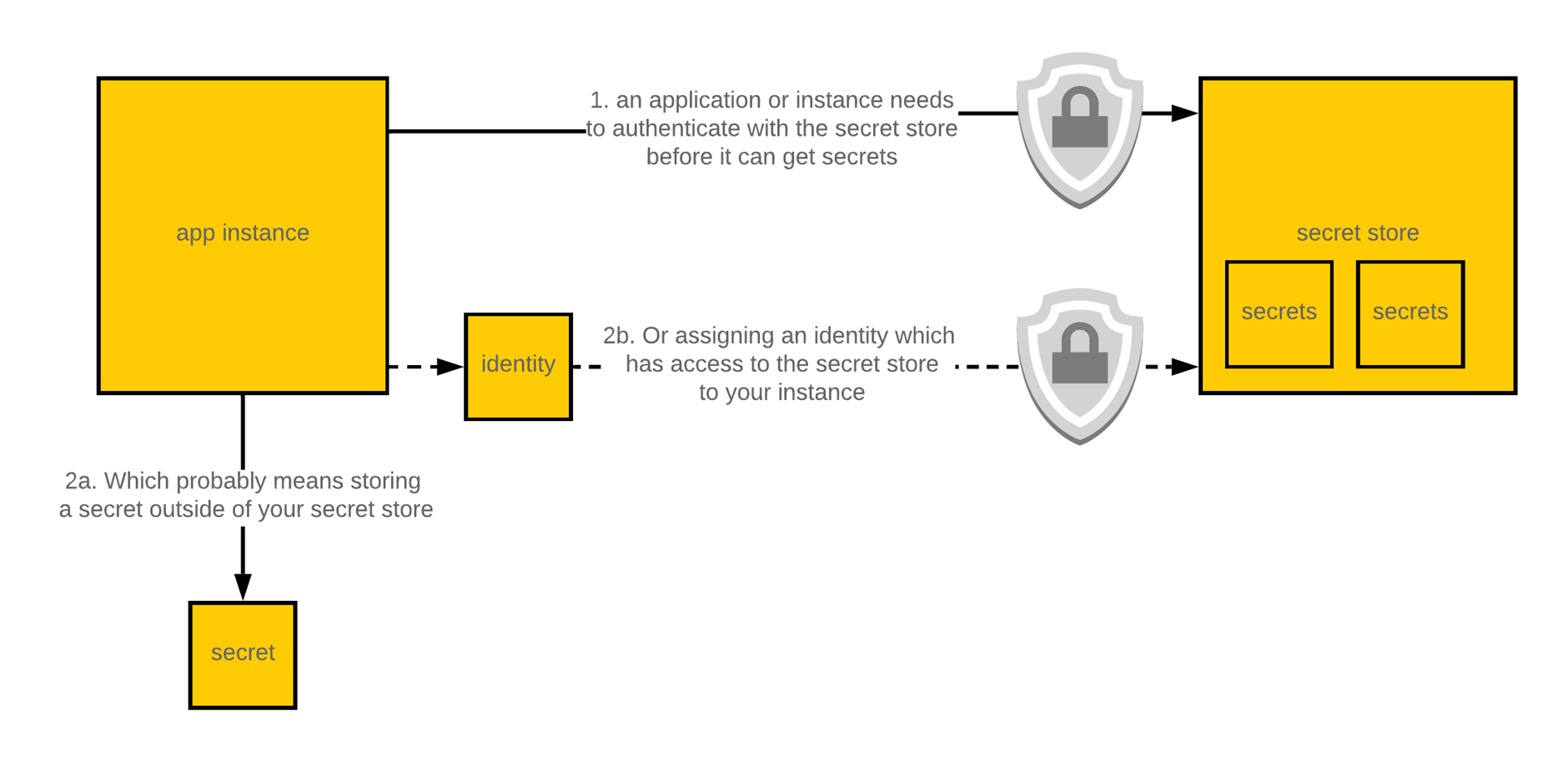
With this in mind:
- Always factor the initial trust into the design of a solution: think about when and where initial trust needs to be established, and ensure there is a good answer for handling secrets which exist out of band to your primary secret store
- Always use identity-based access control (AWS IAM roles, Azure Managed Service Identities, etc) where possible – this often helps with the initial trust problem, and reduces the need for secrets when accessing other cloud resources
- Having to store the initial trust secret outside of your primary secret store should not be considered a deal breaker – 99% of your secrets will still be stored and managed in the primary secret store
- Establishing the initial trust in application instances is harder than doing so on your automation servers and presents some interesting challenges:
- The number of instances: you are probably talking about 10s of automation systems vs 100s or 1000s of application instance
- Application instances are naturally more exposed, whilst automation tooling is typically secured on an internal network
Secret management solution requirements
A comprehensive secret management solution should meet these requirements:
• Secrets are not stored in plain text at-rest
• Secrets in-transit are not sent in plain text
• Encryption keys cannot be exported
• Encryption keys can be rotated
• Highly available – does not impact the availability applications which depend on it
• Secrets should be immutable through versioning (applications should be able to reference specific secret versions)
• Audited operations (E.g create, read, update, delete)
• Easy to use and well understood or you risk people reverting to lazy and insecure processes
Tooling
So now we have covered the challenges and requirements, lets move on to different types of tooling which is availabe. There are 3 categories which most secret management solutions fit in to:
• File / SCM encryption: storing encrypted files source control
• Automation and orchestration tooling: storing secrets in your pipeline or configuration management tooling
• Secret management service: storing secrets in a dedicated application/service
For each category, I will explain the advantages and disadvantages, provide some examples of tools, and display a typical workflow.
Tooling: File / SCM encryption solutions
Tools in this category include:
Encrypting data and storing it in git is a common pattern for low-cost secret management solutions. It solves the common problem of plaintext secrets being stored in git – and subsequently on the workstation of any developer who has worked on that code base. The nature of these solutions means you open the door to all the usual benefits of storing something in source control (branching, diffs, pull requests, traceability, rollback, etc).
The tooling in this category are all free open source projects, and they typically comprise of an executable or script which is combined with a private key to facilitate encryption and decryption operations. Other than the key management, there isn’t any infrastructure to provision or manage so the barrier to entry is low.
Key management within these tools primarily rely on manually generated GPG or PGP keys which coupled with the fact that files need to be re-encrypted and committed back into git, makes rotation of keys difficult, in which case rotation is more happen reactively rather than pro-actively, which is important to consider but might be fine depending on your requirements. There are also auditing issues due to the at-rest nature of this solution architecture.
The ability to encrypt selective parts of a file rather than the entire file is a fundamental differentiator between the available tooling in this category, as having meaningful diffs when tracking changes to files in source control is a nice to have. Although, encrypting selective parts of a file might require storing metadata such as key references within a file, which changes the structure, so you might need to get a little creative when it comes to consuming the contents in downstream systems.
Enforcing this across an organization is challenging as these are not centralized solutions, but adoption is straight forward within the context of a team. On the flip side, this is a good fit implementations outside of an organization such as an open source project where a centralized solution is not going to work.
In my opinion, Mozilla SOPS is the leader in this category
• Key management can be offloaded to AWS/Azure/GCP cloud KMS services
o Granular access to this key can be managed through cloud IAM permissions
o This improves auditing as you can track decrypt operations on this key
• Can partially encrypt files for meaningful diffs
• Implements Shamir’s secret sharing which provides flexibility for key management
Example workflow: File / SCM encryption
This is a typical workflow for this category of tooling. You could perform decryption either on your automation tooling or on the target application instance

Summary: File / SCM encryption
Advantages
Minimal infrastructure to manage
Secrets are version controlled
Aligns with GitOps workflows
Low effort and cost
Disadvantages
Requires key management
Auditing issues
Rotation of keys
Not a centralized solution
Tooling: Automation systems
Tools in this category include:
• Chef
• Puppet
• Jenkins
There is a range of automation tools which live between development teams and production systems, this primarily covers CI/CD systems and configuration management tooling.
Unfortunately, secret management is often a secondary concern for most automation systems, and implementations here may have shortcomings in security or functionality when compared to dedicated secret management solutions, so be sure to review the solution capabilities against the points listed in the Secret management solution requirements section. You probably have CI/CD tooling AND configuration management tooling so leveraging the secret management capabilities of disparate orchestration tooling can result in fragmentation, as exposing secrets outside of the context of jobs within that system is usually difficult.
Organizations who have adopted multiple orchestration tools in a given space (different teams using different CI/CD tools) are going to find it harder still to find consistency when depending on secret management capabilities these systems.
Putting secrets into these systems is performed by an operator through a CLI or UI portal, and the secrets are then stored in the server. Consuming these secrets is done through an automation pipeline or job, which will typically have a framework for transforming a tokenized file by substituting the tokens with their desired values.
As this category of tooling is focussed on automation, integrating the secrets management into a release process is trivial, and there are often mechanisms for scoping secrets to specific environments or deployment targets which can simplify environment specific configuration.
Traceability of secrets here is limited, changing a secret is a straight forward operation but there isn’t usually any mechanism for answering who made a change, when it was made, and why it was made.
Example workflow: Automation systems

Summary: Automation systems
Advantages
Built-in automation means easy integration with the release process
Low barrier to entry as most organizations have this tooling already
Centralized solution
Disadvantages
Security and compliance can be limited
Functionality varies across tools in this space
Multiple orchestration tools cause fragmentation
Another source of truth
Poor traceability
Tooling: Secret service
Tools in this category include:
• Azure Key Vault
• AWS Parameter Store
• Vault (Hashicorp)
• KeyWhiz (Square)
• com
Storing secrets in a designated web service is becoming more popular as it opens the door for taking a more dynamic approach to secrets, but this space is less mature than the other categories. Access to secrets is done through an API which potentially means access to the system can be very granular and security can be tightly locked down.
There are a range of tools in this category – some hosted and others on-premise / self-hosted style solutions.
The most common are probably the generic cloud provider services such as AWS parameter store or Azure Key Vault. Azure Key Vault has limitations for assigning granular permissions, as access to an individual Key Vault must be granted on an all-or-nothing basis, so you have to provision multiple discrete Key Vaults to provide isolation between applications and environments which can increase complexity. Assuming your application instances are also running in the same cloud provider, then assigning identities to application instances will help with the initial trust.
There are also SaaS style hosted offerings – EnvKey is an interesting solution which is more opinionated than the cloud provider solutions. It treats applications and environments as first-class citizens which makes integration really straight forward, but this does come with a cost due to the licensing model being per-user. Although this is probably the most expensive solution, you have to factor in the potential cost savings when compared to rolling your own solution. Again, you have the initial trust problem where you still need to manage the secret which grants you application access to envkey.
There are self-hosted solutions such as Hashicorp Vault, which is the de-facto in this category as it provides some neat features such as dynamic secrets and can also perform encryption as a service to other applications within your environment. There is flexibility in the implementation as the backend storage is abstracted to support a number of storage and database providers, however on the whole this solution requires a significantly more effort to implement and operate at scale in comparison with the cloud/hosted services.
For all tools in this category there is flexibility in terms of integration for consuming secrets: An application can retrieve the secrets at runtime through a direct integration, or a pipeline can retrieve secrets and inject them into a config file or environment variables.
Integrating an application directly with a secret service places this dependency firmly in your critical path, so it is absolutely vital to plan for failure. If your secret management service goes down and it takes your application that’s unacceptable, in comparison to a scenario where you are retrieving secrets inside a CI/CD pipeline – being unable to deploy for half an hour is probably an acceptable impact.
You do need to consider ownership and deployment models – having a centralized service means consistent security and compliance, whilst individual teams or departments managing their own instances provides more control and could mitigate the impact of a centralized system failing.
Traceability of changes can be difficult poor here, although secrets are usually individually versioned you probably can’t answer questions such as who made a change, why it was changed, etc that you would be able to answer with a git-based solution. It is also difficult to describe the state of the system as a whole – as individual operators are often performed manually by operators this needs more rigor to ensure alignment with release processes.
Example workflow: Secret service

There might look like a simple workflow at a glance, but the effort is often heavy upfront in the design and implementation of the secret service. You also need to think about how the application integrates with the secret service – depending on how many languages and frameworks are used to write applications then this can be non-trivial to ensure consistent approaches across numerous teams.
If you go down the direct application integration then be aware the initial trust problem becomes more challenging, as you need to bootstrap all of your application instances in comparison to only bootstrapping your automation servers.
Advantages
Strong security features
Fine-grained access control
Dynamic secrets (Hashicorp vault)
Disadvantages
The high effort is a barrier to adoption
Can impact application availability
Another source of truth
Poor traceability of changes
Service may be internet-facing (cloud / hosted)
But Kubernetes handles secrets?
First of all – Adopting a k8s specific solution is fine if your entire estate is running k8s, otherwise, you might want to look at a more general solution to avoid fragmentation.
Kubernetes does not actually drastically change the approach when it comes to secret management, whilst it does open the door to some nifty solutions (native k8s secrets, helm-secrets, sealed-secrets) which only exist within the k8s ecosystem, when you drill down, they still experience the same challenges as other solutions.
The native k8s secret resource has major security gaps in its current state, as secrets are stored and distributed across cluster nodes in plain text. There is beta support for encrypting secrets, but then an external KMS provider is also required to also avoid storing the master key-encryption-keys in plain text. Eventually, this is going to improve over time but in its current state, it’s bad.
The initial trust problem also requires a higher level of granularity to solve in k8s (or any container orchestration platform), as to enable fine-grained access to secrets on a per-application basis your trust boundary is an individual pod rather than an entire machine (cluster node). Unfortunately, the options for assigning identities on a per-pod basis are immature (AWS, Azure) and you may end up having to resort to per-machine identities which means poor isolation between applications. Factoring this into your cluster design could lead to provisioning and managing additional isolated clusters to meet security requirements.
When using native k8s secrets you will need to think about how the secrets get into Kubernetes in the first place – You typically need to leverage tooling from the above categories to aid this process.
Taking all of that into account, there are some benefits to using the native k8s secrets, such as the ease of use and simple integration with applications, just beware of their limitations!
Rating of different categories
Here are some ratings in my opinion of key metrics for the different categories of tooling. There are exceptions within each categories, but on the whole this is where I feel most tools within a given category sit from a high level.

List of available tooling
Here is an overview of all the secret management tooling which I am currently aware of. If there are any established tools missing from this list, then please leave a comment.

There are several open source secret management projects which build upon AWS resources (KMS, DynamoDB, s3, etc) and provide a CLI for CRUD operations. While they are quite neat projects, in my opinion they don’t offer much over the native AWS parameter store service other than the fact that they are not constrained by the parameter store service limits. I have labelled these as “AWS wrapper” in the table above.
Wrapping it all up
A comprehensive strategy will typically include a combination of multiple solutions. You could use a git-based solution as the source of truth, then use a pipeline script to put these into a secret service where the applications consumes secrets from, which combines a familiar developer experience with granular and audited access to secrets.
Consider what secret management capabilities are required at individual stages of your software development life cycle to build up a list of requirements, then you can map these requirements to techniques and identify tooling which then meets these needs.
Mapping techniques and tooling to stages of your workflow would look like this:

Some final thoughts:
• The initial trust (or bootstrapping) issue is not unique to a particular tool or approach, factor it into your design
• Think about your entire workflow from development to production
• The different categories of tooling can complement each other
• There isn’t a perfect solution, if you can implement a solution which is better than what you currently have, then go for it as its a step in the right direction!
Things you will learn
Related content
Need help plotting a route to the cloud?

